Contents
Introduction
Recently I’ve worked with a web API, the Cometdocs API, in order to use their converter of documents, particularly for automating some conversions from PDF documents to Excel spreadsheets for data extraction.
I wanted to use this API from my two favorite development platforms: Java and .Net/C#, so I needed to build what is called a language binding, i.e. a small library that acts as a proxy between the application code and the web API.
The development of these two bindings was really interesting from a technical point of view, and I’ve learned a bunch of things during the process.
I’d like to share the interesting stuff with you, it should be of interest even if you don’t have any plan for interacting with a web API because all the technologies and techniques I’ve used (the HTTP protocol, JSON data binding, SSL/TLS…) are applicable to other types of developments.
This series is made of three articles:
- this article that describes the general principles, without diving too deeply into technical details that would be specific to a given platform
- an article about the Java implementation: How to build a Java binding for a web API
- and one about the .Net implementation: How to build a .Net binding in C# for a web API
You should read this article first before diving into implementation details specific to Java or .Net/C#, but feel free to navigate between this article and the article dedicated to your platform.
Some historical background
Some years ago SOA was THE concept you had to implement in your IT infrastructure to build web-services, but the promise of enhanced quality and efficiency often fell short in part due to complex standards (all the WS-* stuff) and complex tools.
This was not bad for everybody: vendors sold a lot of pipes and we as developers and integrators had some work to build the plumbing for years.
The best thing with this flop is that we realized that we did not need complex standards, technologies and tools to serve the business, but a standard, solid and KISS software foundation.
This universal platform progressively appeared as the web ecosystem was developing: it was the good old HTTP stack.
Concerning the data format we progressively dropped the verbose XML and choose a lighter format: JSON, whose success is explained by both its inherent qualities and the fact it is a superset of the objects representation used by Javascript, the ubiquitous language (some would say “thing”) of the web world (both on the client and on the server with Node.js).
If you add REST into the equation as a way of representing the web resources you obtain a simple and efficient stack that is becoming more and more popular and is used by the main web players like Twitter or Google to build their web-services.
But to quickly build easily accessible web-services you don’t have to stick zealously with all this stack and you can pick only the parts you need for your current situation: you can use XML instead of JSON if you think its a better fit for you API, in the same way as AJAX (remember Asynchronous JavaScript and XML) is often used with JSON or another raw format instead of XML.
API Presentation
Functionally the Cometdocs API gives you access to all the document management features available through their web-site: files upload and download, conversion and sharing.
Technically the Cometdocs API is based on HTTP and JSON but it does not (yet) use REST.
Indeed the Cometdocs API rather looks like the kind of API you use when you have a binary interface: a set of methods.
You interact with them using some form-encoded HTTP/POST requests.
So contrary to REST which would expose resources (in this case files and folders) through URLs and uses HTTP/GET requests to read them (e.g. when downloading a file or getting the content of a folder) and HTTP/POST requests to write them (e.g. when uploading a file into a folder), the Cometdocs API uses HTTP/POST requests for both.
Note that this is not an issue by itself and from the point of view of a language binding implementer it does not make implementation more complex: you send requests in a given format, and read some responses in another format.
The only (minor) drawback is that direct testing using a web-browser or some web scrappers is not obvious.
As for the client of your language binding it does not change anything at all, it sees the same API whatever the underlying implementation, and this is precisely one of the purpose of a language binding.
The Cometdocs API is consistent, well documented (see the Cometdocs API documentation) and Cometdocs even provides an online demo of the API in the form of HTML forms (see: Cometdocs API demo) which almost completely offsets the lack of a more RESTful API.
So forging requests for the API is a relatively straightforward process, except for the file upload (more on this point later).
As an example, to download a file you hit the https://www.cometdocs.com/api/v1/downloadFile entry-point with this payload:
token=12345678-1234-1234-abcd-abcd12345678&id=1234
where “token” is your authentication token and “id” is the id of the file you want to retrieve.
And the Cometdocs API responds with the content of the requested file:
HTTP/1.1 200 OK ... Content-Length: 1138 Vary: Accept-Encoding Connection: close Content-Type: text/plain The peanut, or groundnut (Arachis hypogaea), is a species in the legume or "bean" family (Fabaceae). The peanut was probably first domesticated and cultivated in the valleys of Paraguay.[1] It is an annual herbaceous plant growing 30 to 50 cm (1.0 to 1.6 ft) tall. The leaves are opposite, pinnate with four leaflets (two opposite pairs; no terminal leaflet), each leaflet is 1 to 7 cm (⅜ to 2¾ in) long and 1 to 3 cm (⅜ to 1 inch) broad. The flowers are a typical peaflower in shape, 2 to 4 cm (0.8 to 1.6 in) (¾ to 1½ in) across, yellow with reddish veining. Hypogaea means "under the earth"; after pollination, the flower stalk elongates causing it to bend until the ovary touches the ground. Continued stalk growth then pushes the ovary underground where the mature fruit develops into a legume pod, the peanut – a classical example of geocarpy. Pods are 3 to 7 cm (1.2 to 2.8 in) long, containing 1 to 4 seeds.[2] Peanuts are known by many other local names such as earthnuts, ground nuts, goober peas, monkey nuts, pygmy nuts and pig nuts.[3] Despite its name and appearance, the peanut is not a nut, but rather a legume.
Design
General rationales
Whatever your development platform, when you’re interacting with an external system you try to abstract it by encapsulating it in a custom component, typically a class, that will not let any technical stuff to leak outside, particularly in your application code.
In our case to interact with Cometdocs you don’t want to clutter the code with forging of HTTP requests, especially non trivial POST requests.
You want to use high-level methods and objects, not strings of text or arrays of bytes.
This is precisely the role of a language binding, being a wrapper that encapsulates all the plumbing necessary to use the HTTP API and acts as a proxy: it connects to the server, builds the requests with your parameters, sends them, interprets the results and returns some high-level objects in a transparent manner.
This way the application code, e.g. if you build a graphical file browser for Cometdocs, is completely decoupled from the low level layers, and is not polluted with technical details not relevant when implementing higher level features.
There is a second good reason to build such a binding: reusability.
Once you’ve implemented and packaged your language binding you can use it in any other project that needs to interact with the API, without having to rethink about how you communicate with the web API and without having to rewrite and duplicate code.
I’ll illustrate these principles starting with a general presentation of the Cometdocs client class, then I’ll describe the mapping of the authentication token and the files and folders structures, and finally talk of the files upload methods.
The client class
The client class is the facade used by the application code to interact with the Cometdocs API, it’s the only class the application code needs to instantiate.
Each of the entry-points exposed by the Cometdocs API has been mapped to a method in the client class: e.g. the https://www.cometdocs.com/api/v1/authenticate entry-point is mapped to the “authenticate” method.
The client methods signatures follow exactly the API entry points signatures; this is all good except that consequently the first parameter of each authenticated method is an authentication token that must be provided by the caller.
This is not really an issue but to make the binding a little easier to use creating an “AuthenticatedClient” class would be a good idea, maybe for a next version…
In the first version of the language binding there was only a concrete client class named “Client” directly used by the application code this way:
Client client = new Client();
AuthenticationToken authToken = client.authenticate("john.doe@gmail.com", "secret", "a1234-b5678-c9101-d21314");
But while I’m not an object-oriented design fanatic I’ve made two “enhancements” to this simple implementation:
- use an interface named “Client” (“IClient” in C#) to extract the functional contract implemented by the concrete “client” class which is now named “ClientImpl” (“Client” in C#) and is not “public” visible anymore but “package” (“internal” in C#) visible
- do not let the application instantiate the “ClientImpl” class itself but instead delegate this responsibility to a factory class named “ClientFactory“
Following these two principles this gives:
Client client = ClientFactory.getClient();
AuthenticationToken authToken = client.authenticate("john.doe@gmail.com", "secret", "a1234-b5678-c9101-d21314");
with “Client” being here an interface rather than a class.
Not a revolution but certainly cleaner from an OO design point of view.
The current factory implementation is really basic, it only instantiates a new “ClientImpl“:
Client getClient()
{
return new Client();
}
The main purpose of this kind of factory is to uncouple application code from the burden of instantiating correctly the right class.
So the application code does not need to know if there is more than one implementation of the “Client” interface.
Moreover the factory can manage complex object life-cycles using a pooling policy: instead of instantiating a new client each time it can try to recycle older clients not used anymore.
And finally it’s useful if we latter want to switch an implementation for another in case the first one become deprecated.
To illustrate this last point imagine that somebody contributes a new “AwesomeClient” class to replace the initial “ClientImpl” class, with our factory in place we only need to update one line of code:
Client getClient()
{
return new AwesomeClient();
}
and every application code will benefit from the “AwesomeClient” class without having to be updated:
Client client = ClientFactory.getClient();
I’ve not applied this principle of separation of the interface and the implementation for simpler structures like the authentication tokens, the conversion types, and the files and folders because in these cases the benefits are really not obvious so I’ve stuck with a more general principle: “simpler is better”.
Implementations: Java, .Net/C#
The authentication token class
When you authenticate with the API using the authenticate entry-point you get back a small token that will identify you for the subsequent API calls.
This is a good thing for at least two reasons:
- security: you don’t have to pass your authentication data each time, which would multiply the risk of them being stolen with a man-in-the-middle attack
- session: a token identify a user but can also identify a set of related interactions with the API, a session
As of now this token is a simple string like “12345678-1234-1234-abcd-abcd12345678” but I’ve chosen not to expose it directly but rather to wrap it in a dedicated structure named “AuthenticationToken“:
+---------------------+ | AuthenticationToken | +---------------------+ | value : string | +---------------------+
Here are some rationales for doing so:
- a structure gives to this raw bunch of characters some semantics
- in case the underlying value changes no need to update the application code, only the API client is updated
- if for any reason, like tracking, we need to add some other properties like a timestamp with the token issuance time, another with the expiration time, we won’t break anything outside or inside the component
Implementations: Java, .Net/C#
The conversion type class
Here is another (slightly) more complicated abstraction: the conversion type class.
Indeed the Cometdocs API represents a conversion from a file format to another as a compacted text string like “PDF2XLS“.
This is not the kind of raw string you want to work with at the application code level; instead you want a high-level representation of the same entity whose you can explore properties without worrying about parsing.
So to represent it in a more object-oriented manner the ConversionType class has been created:
+----------------+ | ConversionType | +----------------+ | from : string | | to : string | +----------------+
The rationales are the same as for the authentication token class: we want to abstract the notion of conversion so that the application code works with an abstraction rather than a specific implementation.
The files and folders types
The Cometdocs API exposes additional types: file, folder, category, conversion and notification.
The file type has been mapped to a “FileInfo” type because it only carries some metadata about the file content, not the content itself, so it’s more like a handle used to identify a file; this is the file representation used most often because you only need content when you upload or download a file, otherwise you just need a reference.
To represent a file with content I’ve created a “File” class which inherits from “FileInfo“:
+-----------------------+
| FileInfo |
+-----------------------+
| id : int |
| name : string |
| extension : string |
| size : int |
| hasConversions : bool |
| ownerId : int |
| ownerName : string |
+-----------------------+
^
|
+------------------+
| File |
+------------------+
| content : byte[] |
+------------------+
This choice of inheriting is debatable because a “File” could also be considered as the aggregation of some metadata, the “FileInfo“, and some content, the array of bytes:
+------------------+ | File | +------------------+ | info : FileInfo | | content : byte[] | +------------------+
I’ve made this choice for simplicity.
In the same manner the notion of folder is split into two classes: “FolderInfo” that holds the name and id, and “Folder” that holds the tree of sub-folders and files, and inherits from “FolderInfo“:
+---------------+
| FolderInfo |
+---------------+
| id : int |
| name : byte[] |
+---------------+
^
|
+--------------------+
| Folder |
+--------------------+
| folders : Folder[] |
| files : FileInfo[] |
+--------------------+
Note that in the “Folder” class the files are represented using the “FileInfo” class because you never handle a tree of files with content, but folders are represented using the “Folder” class because we want a recursive structure.
Implementations: Java, .Net/C#
The file upload methods
Uploading a file is about sending the bytes that make it to the server, this is done with the “uploadFile” entry-point that takes some simple parameters like the authentication token and a folder id and a bunch of bytes.
This is typically the kind of complex (well more or less depending on your platform) task you want to make as simple as possible to use from application code, especially because it’s one of the core feature of the system we’re building an API for.
So I’ve written some overloads:
- the first takes a “File” object and sends its binary content
uploadFile(token:AuthenticationToken, file:File, [folder:int])
- another ask for a local file path and will open it and streams its content
uploadFile(token:AuthenticationToken, file:string, [folder:int])
- the last one uses a stream and reads its bytes.
uploadFile(token:AuthenticationToken, file:stream, [folder:int])
To avoid any redundancy only the last one, which uses a stream, is a “true” method, the two others acting as proxies that simply forward the call: the first one creates a bytes stream in memory (a ByteArrayStream in Java and a MemoryStream in .Net), the second one creates a file stream (FileInputStream in Java and a FileStream in .Net).
This is possible thanks to the high level abstraction a stream represents: it can be anything that can be read chunk by chunk.
Implementations: Java, .Net/C#
The web/HTTP client
The first component you need to interact with a web API is an HTTP client, a kind of small browser without any display capability of the content.
Its role is to forge the HTTP requests, to send them to the server, and to retrieve the response for you.
It does all the hard work for you like taking care of building valid request because forging them by hand can be tricky: e.g. if you forget a little separator “\r\n” your request won’t be understood by the server or worst it could be misinterpreted and do unexpected things.
When you’re using a REST API you have to emit a lot of GET requests because one “method” call is often mapped to one GET request; and while GET is the simplest request you can build it’s not that trivial.
Implementations: Java, .Net/C#
A not that simple GET
Here is a basic GET of the “google.com” homepage done using Wget, a command line HTTP client bundled with any Linux distribution or Cygwin under Windows:
first we ask for the resource at the root of its domain google.com
GET / HTTP/1.1 User-Agent: Wget/1.13.4 (cygwin) Accept: */* Host: google.com Connection: Keep-Alive
to what Google responds:
HTTP/1.1 301 Moved Permanently Location: http://www.google.com/ Content-Type: text/html; charset=UTF-8 ...
OK, the resource we’re looking at is located in the subdomain “www.google.com”, so Wget sends another GET request:
GET / HTTP/1.1 User-Agent: Wget/1.13.4 (cygwin) Accept: */* Host: www.google.com Connection: Keep-Alive
And finally Google responds:
HTTP/1.1 302 Found Location: http://www.google.fr/ ...
“…” is a bunch of headers and data.
This time the server indicates that we should find what we’re looking for on a national domain.
So Wget emits another GET for this local page:
GET / HTTP/1.1 User-Agent: Wget/1.13.4 (cygwin) Accept: */* Host: www.google.fr Connection: Keep-Alive
This time Google is happy and returns us the content, i.e. the HTML page:
200 OK ...
Quite a long conversation to get a bunch of markup!
So as you see speaking with a web server is far from trivial because HTTP is a rich protocol with a lot of metadata and you can’t reasonably handle it yourself.
GETting from Cometdocs
When you want to retrieve data from the Cometdocs API and you don’t need to transmit any parameters you can use a simple HTTP/GET request.
As of now there is three entry-points that do not require any parameters, in part because they are “public”, i.e. you don’t need to be authentified by a token to use them: getCategories, getConversionTypes and getMethods.
If you GET “getCategories” you get the tree of all the categories you can use to organize documents:
# wget -qO- --no-check-certificate https://www.cometdocs.com/api/v1/getCategories
{"categories":[{"id":98,"name":"Activism","subcategories":[]},{"id":81,"name":"Art","subcategories":[{"id":82,"name":"Comics","subcategories":[]},{"id":87,"name":"Drawings","subcategories":[]},{"id":85,"name":"Maps","subcategories":[]},{"id":88,"name":"Other","subcategories":[]},{"id":83,"name":"Photos","subcategories":[]},{"id":86,"name":"Pictures","subcategories":[]},{"id":84,"name":"Posters","subcategories":[]}]},{"id":8,"name":"Business","subcategories":[{"id":9,"name":"Accounting","subcategories":[]},{"id":19,"name":"Architecture","subcategories":[]},{"id":15,"name":"Books","subcategories":[]},{"id":22,"name":"Economics","subcategories":[]},{"id":20,"name":"Engineering","subcategories":[]},{"id":10,"name":"Finance","subcategories":[]},{"id":13,"name":"Flyers & Brochures","subcategories":[]},{"id":14,"name":"Letters","subcategories":[]},{"id":12,"name":"Marketing","subcategories":[]},{"id":23,"name":"Other","subcategories":[]},{"id":17,"name":"Presentations","subcategories":[]},{"id":21,"name":"Project Management","subcategories":[]},{"id":11,"name":"Small Business&Entrepreneurs","subcategories":[]},{"id":18,"name":"Spreadsheets","subcategories":[]},{"id":16,"name":"Templates","subcategories":[]}]},{"id":24,"name":"Career","subcategories":[{"id":26,"name":"Cover Letters","subcategories":[]},{"id":27,"name":"General","subcategories":[]},{"id":29,"name":"Other","subcategories":[]},{"id":28,"name":"Presentations","subcategories":[]},{"id":25,"name":"Resumes & CVs","subcategories":[]}]},{"id":40,"name":"Education","subcategories":[{"id":41,"name":"Essays & Thesis","subcategories":[]},{"id":43,"name":"Homework","subcategories":[]},{"id":47,"name":"Other","subcategories":[]},{"id":44,"name":"Presentations","subcategories":[]},{"id":45,"name":"Spreadsheets","subcategories":[]},{"id":42,"name":"Teaching Material","subcategories":[]},{"id":46,"name":"Textbooks","subcategories":[]}]},{"id":99,"name":"Health","subcategories":[]},{"id":66,"name":"History","subcategories":[{"id":72,"name":"Africa","subcategories":[]},{"id":70,"name":"Asia","subcategories":[]},{"id":71,"name":"Australia","subcategories":[]},{"id":67,"name":"Europe","subcategories":[]},{"id":68,"name":"North America","subcategories":[]},{"id":73,"name":"Other","subcategories":[]},{"id":69,"name":"South America","subcategories":[]}]},{"id":100,"name":"Humor","subcategories":[]},{"id":1,"name":"Legal","subcategories":[{"id":3,"name":"Contracts & Agreements","subcategories":[]},{"id":5,"name":"Forms","subcategories":[]},{"id":2,"name":"Laws","subcategories":[]},{"id":7,"name":"Other","subcategories":[]},{"id":4,"name":"Statements","subcategories":[]},{"id":6,"name":"Taxes","subcategories":[]}]},{"id":89,"name":"Lifestyle","subcategories":[{"id":94,"name":"Culture","subcategories":[]},{"id":90,"name":"Fashion","subcategories":[]},{"id":91,"name":"Food & Drinks","subcategories":[]},{"id":93,"name":"Home & Family","subcategories":[]},{"id":92,"name":"Relationships","subcategories":[]}]},{"id":74,"name":"Literature","subcategories":[{"id":75,"name":"Fiction","subcategories":[]},{"id":76,"name":"Non-fiction","subcategories":[]},{"id":80,"name":"Other","subcategories":[]},{"id":78,"name":"Poetry","subcategories":[]},{"id":79,"name":"Short Stories","subcategories":[]},{"id":77,"name":"Writings","subcategories":[]}]},{"id":95,"name":"News and Current Events","subcategories":[]},{"id":96,"name":"Pets","subcategories":[]},{"id":59,"name":"Politics","subcategories":[{"id":64,"name":"Books","subcategories":[]},{"id":65,"name":"Other","subcategories":[]},{"id":63,"name":"Presentations","subcategories":[]},{"id":62,"name":"Reports","subcategories":[]},{"id":61,"name":"US politics","subcategories":[]},{"id":60,"name":"World Politics","subcategories":[]}]},{"id":30,"name":"Science","subcategories":[{"id":31,"name":"Academic Research","subcategories":[]},{"id":34,"name":"Biology","subcategories":[]},{"id":38,"name":"Books","subcategories":[]},{"id":33,"name":"Chemistry","subcategories":[]},{"id":35,"name":"Mathematics","subcategories":[]},{"id":39,"name":"Other","subcategories":[]},{"id":36,"name":"Physics","subcategories":[]},{"id":32,"name":"Publications","subcategories":[]},{"id":37,"name":"Social Science","subcategories":[]}]},{"id":101,"name":"Sport","subcategories":[]},{"id":48,"name":"Technology","subcategories":[{"id":58,"name":"Bio-technology","subcategories":[]},{"id":50,"name":"Computers","subcategories":[]},{"id":54,"name":"Consumer Electronics","subcategories":[]},{"id":57,"name":"Green Technology","subcategories":[]},{"id":49,"name":"Internet","subcategories":[]},{"id":51,"name":"Mobile Phones","subcategories":[]},{"id":55,"name":"Presentations","subcategories":[]},{"id":52,"name":"Software","subcategories":[]},{"id":56,"name":"Spreadsheets","subcategories":[]},{"id":53,"name":"Web Apps","subcategories":[]}]},{"id":97,"name":"Vehicles","subcategories":[]}],"status":0,"message":"OK"}
If you GET “getConversionTypes” you get the list of all supported files conversions:
# wget -qO- --no-check-certificate https://www.cometdocs.com/api/v1/getConversionTypes
{"conversionTypes":["2PDF","PDF2BMP","PDF2DOC","PDF2DWG","PDF2DXF","PDF2GIF","PDF2HTML","PDF2JPEG","PDF2ODP","PDF2ODS","PDF2ODT","PDF2PNG","PDF2PPTX","PDF2TIF","PDF2TXT","PDF2XLS","XPS2BMP","XPS2DOC","XPS2GIF","XPS2HTML","XPS2JPEG","XPS2ODP","XPS2ODS","XPS2ODT","XPS2PNG","XPS2TIF","XPS2TXT","XPS2XLS"],"status":0,"message":"OK"}
And finally if you GET “getMethods” you get the list of all the methods exposed by the Cometdocs API:
# wget -qO- --no-check-certificate https://www.cometdocs.com/api/v1/getMethods
{"methods":["authenticate(clientKey, username, password, validity=null)","refreshToken(token, validity=null)","invalidateToken(token)","getFolder(token, folderId=null, recursive=0)","getConversions(token, fileId=null, includeAvailable=0)","downloadFile(token, id)","uploadFile(token, folderId=null)","uploadFileFromUrl(token, url, name=null, folderId=null)","convertFile(token, id, conversionType)","getConversionStatus(token, fileId, conversionType)","getSharedFiles(token)","getNotifications(token)","deleteFile(token, id, deleteRevisions=1)","deleteFolder(token, id)","getConversionTypes()","getCategories()","getPublicFiles(token, categoryId=null)","sendFile(token, id, recipients, sender=null, message=null)","createFolder(token, name, folderId=null)","getMethods()"],"status":0,"message":"OK"}
Posting data
More often than not when you use a web API you must transmit some data to the server, in the same way you sometimes have to pass some parameters to a function when programming in your favorite language.
There is at least three ways of passing these data:
- using the request URL parameters section: “some.server.com/api/getUser?id=123“, this is used by HTML forms when the “method” attributes is set to “get”
- using the request URL path section: “some.server.com/api/user/123“, this is used by REST APIs because it cleanly represents a resource, the user number 123
- using the request body: you use a POST request to “some.server.com/api/getUser” with some attached content “id=123”, it’s used by HTML forms when “method” is “post”
As I’ve said in the presentation section the Cometdocs API uses only the third format.
As an example when you hit the Cometdocs API “sendFile” entry-point you pass this bunch of data:
token=12345678-1234-1234-abcd-abcd12345678&id=123&recipients=john@example.org;bob@example.org&sender=tom@example.org&message=Here+is+the+report
It’s a set of key value pairs, a dictionary, and this is exactly the abstraction used by all the HTTP clients I know.
Good tools to sniff such conversations are Wireshark and Fiddler.
Files upload
As you’ve seen forging HTTP/POST requests is a relatively simple task…at least for simple payloads, like form parameters, but when you want to transfer more esoteric data like entire files things become a little tricky.
First you have to manage the binary data themselves, e.g. if you transfer PDF or XLS files; secondly you must build a multipart request, that is a request with multiple payloads: some simple forms text data as usual plus another payload for the file content itself.
The request has to follow a strict format to be understood by the server: you first choose a delimiter, the boundary, to separate the different parts of your payload, then you inject your individual sub-payloads into the whole request payload.
As an example to upload this simple bunch of text:
The peanut, or groundnut (Arachis hypogaea), is a species in the legume or ""bean"" family (Fabaceae). The peanut was probably first domesticated and cultivated in the valleys of Paraguay.[1] It is an annual herbaceous plant growing 30 to 50 cm (1.0 to 1.6 ft) tall. The leaves are opposite, pinnate with four leaflets (two opposite pairs; no terminal leaflet), each leaflet is 1 to 7 cm (⅜ to 2¾ in) long and 1 to 3 cm (⅜ to 1 inch) broad. The flowers are a typical peaflower in shape, 2 to 4 cm (0.8 to 1.6 in) (¾ to 1½ in) across, yellow with reddish veining. Hypogaea means ""under the earth""; after pollination, the flower stalk elongates causing it to bend until the ovary touches the ground. Continued stalk growth then pushes the ovary underground where the mature fruit develops into a legume pod, the peanut – a classical example of geocarpy. Pods are 3 to 7 cm (1.2 to 2.8 in) long, containing 1 to 4 seeds.[2] Peanuts are known by many other local names such as earthnuts, ground nuts, goober peas, monkey nuts, pygmy nuts and pig nuts.[3] Despite its name and appearance, the peanut is not a nut, but rather a legume.
to your Cometdocs store you must send this multipart HTTP/POST request:
POST https://www.cometdocs.com/api/v1/uploadFile HTTP/1.1 Content-Type: multipart/form-data; boundary=815dea07-4013-43c4-8fa1-e1014ad70f33 Host: www.cometdocs.com Content-Length: 1515 Expect: 100-continue --815dea07-4013-43c4-8fa1-e1014ad70f33 Content-Disposition: form-data; name="token" 123bf456-d5bb-4f98-8d9a-a7896dc1970e --815dea07-4013-43c4-8fa1-e1014ad70f33 Content-Disposition: form-data; name="folderId" 38386 --815dea07-4013-43c4-8fa1-e1014ad70f33 Content-Disposition: form-data; name="file"; filename="Peanuts.txt" The peanut, or groundnut (Arachis hypogaea), is a species in the legume or "bean" family (Fabaceae). The peanut was probably first domesticated and cultivated in the valleys of Paraguay.[1] It is an annual herbaceous plant growing 30 to 50 cm (1.0 to 1.6 ft) tall. The leaves are opposite, pinnate with four leaflets (two opposite pairs; no terminal leaflet), each leaflet is 1 to 7 cm (⅜ to 2¾ in) long and 1 to 3 cm (⅜ to 1 inch) broad. The flowers are a typical peaflower in shape, 2 to 4 cm (0.8 to 1.6 in) (¾ to 1½ in) across, yellow with reddish veining. Hypogaea means "under the earth"; after pollination, the flower stalk elongates causing it to bend until the ovary touches the ground. Continued stalk growth then pushes the ovary underground where the mature fruit develops into a legume pod, the peanut – a classical example of geocarpy. Pods are 3 to 7 cm (1.2 to 2.8 in) long, containing 1 to 4 seeds.[2] Peanuts are known by many other local names such as earthnuts, ground nuts, goober peas, monkey nuts, pygmy nuts and pig nuts.[3] Despite its name and appearance, the peanut is not a nut, but rather a legume. --815dea07-4013-43c4-8fa1-e1014ad70f33--
As you see there is a lot of boilerplate that you must respect to the letter if you don’t want your request to be rejected because considered as ill-formed.
The request payload is split into multiple parts: two are form-encoded data to specify the session token and the folder id, the third is the content of the file we’re transferring.
Unless you’re a system programming fanatic the perspective of forging such multipart requests should not delight you, and you hope your favorite web client handles it smoothly.
Implementations: Java, .Net/C#
Data binding
Implementations: Java, .Net/C#
Rationales
Web APIs return data as text streams structured using a standard format: typically XML or JSON.
In your application code you don’t want to manipulate raw strings with all the trouble associated with parsing.
The first thing you can do is working at the format level and use dedicated components that offer an higher level abstraction of this bunch of text.
e.g. if you use XML you have two well known abstractions of an XML document:
- DOM that represents the document as a tree of nodes loaded in memory that you can visit in a random manner
- SAX that instead represents the document as a stream of nodes
But this is not totally satisfactory because you’re still at the data level, and from application code you prefer manipulating real business objects.
So you need a component that interprets the XML or JSON document as a set of business objects, and, if you need to send back data, the other way around too, converting a tree of objects to an XML or JSON document.
This process of mapping a bunch of text to a set of business objects and the other way around is called “data binding” and it really makes working with XML or JSON simpler and IMHO you really should consider it first whenever you have to deal with data formatted in any of these formats and discard it only if you have specific constraints like memory or CPU because data binding can be quite resource consuming.
The Cometdocs case
The Cometdocs API almost always returns an ISO 8859-1 encoded JSON string, except downloadFile that can return anything because the content of a file can be anything.
The first step is to decode the raw binary data returned by the server to obtain the JSON payload, then it must be parsed using a dedicated JSON parser.
For each platform you should easily find a good parser: for .Net I’ve used Json.NET and for Java Gson.
Thanks to these tools most of the time the JSON parsing is transparent and you obtain business objects you can use in your application code (a process that could be called “JSON data binding”): when you read from the API you give the parser a JSON string and it produces some objects, and when you write to the API it translates the platform objects to JSON strings.
90% of the time things works this way but sometimes you must tweak the parsing process to fill the gap between the Cometdocs API representation and yours.
Here is a list of some of these adjustments:
- the Cometdocs API uses numerical booleans, i.e. 0 and 1, which is not supported by all the parsers
- the response status is a numerical code you map to an enum type
- the conversions are expressed in a compacted format like “PDF2XLS” you map to a composite type with fields for the source and destination formats
Security
Security is one of the toughest issue I’ve been faced with while implementing the two language bindings, because you need some minimal background information to make sense of all the process that is sometimes necessary to get things work.
Jumping through all these hoops to manage what could be considered as a secondary issue can be quite frustrating and depressing but fortunately once you’ve grasp some basic principles it starts to make sense.
Implementations: Java, .Net/C#
General background
What is good when you use the HTTP stack is that it comes with a secured version: HTTPS, which is the combination of HTTP and the SSL/TLS security layer.
With SSL/TLS each participant must identify with the other: in our case only the server must prove to the client he really is who he pretends to be, to avoid any possibility of man-in-the-middle attack where the attacker usurps the identity of the server and intercepts the communication between the client and the server.
To establish this proof the client challenges the entity that pretends to be the legitimate server by exchanging messages encrypted in an asymmetric way: the client encrypts with the public key he knows is the key of the entity he wants to talk to, and the server to prove he is this entity decrypts them with a key the entity is the only one to know: its private key.
Without this private key an attacker cannot do anything, and stealing it from the IT infrastructure of a company is far more difficult than sniffing the network of any unprotected client machine interacting with the company servers.
But how the client knows the public key of the server?
This key, along with other trust information, are conveyed in a digital certificate, that the client downloads and stores locally.
On the client computer the certificates are kept in certificates stores: the operating system has a store but any other component can have its own store and will take care of authorizing only the communication with peers whose certificates are in it and are trusted.
As an example each of the Java Runtime Environment (JRE) maintains its own set of certificates in its store, so to be able to use HTTPS with a secured web API you’ll need to reference the certificate used by the API owner, a process I describe in the article dedicated to the Java implementation.
Exporting the certificate
To retrieve the certificate you can use your web-browser (I’ve used Chrome on Windows 7).
First navigate to a page using HTTPS and click the small padlock that shows the browser is using a secured channel to communicate with the website.
You will be presented with this popup:
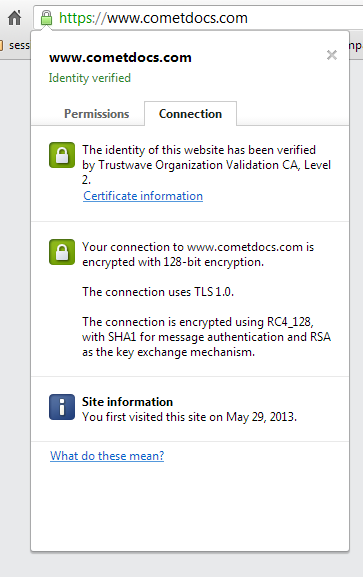
Chrome HTTPS padlock menu
Select the “Connection” tab then click the “Certificate information” hyperlink to see all the certificate properties:

Certificate properties
Go in the “Details” tab and click the “Copy to file” button.
The Windows certificate export wizard will start:
Certificate export wizard
Click “Next“, and select the type of the exported file, you can let the default:
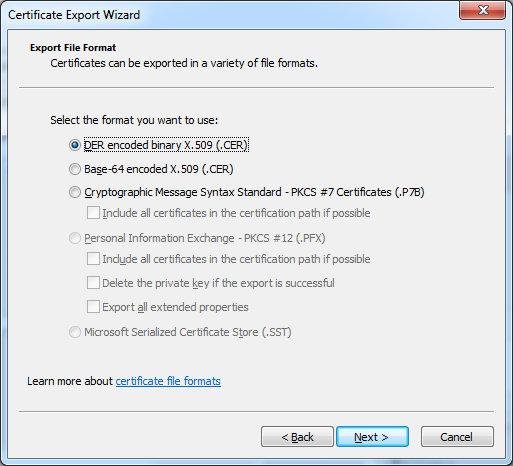
Certificate export type
Choose the file that will store the certificate, either paste the full path or click “Browse” to select a location:

Certificate export file path
The wizard shows you a summary of the export, check it, and click “Finish“:
Certificate export check
The export should be successful:
Certificate export successful
Now you have a local copy of the certificate you’ll be able to reference in any context that requires SSL/TLS security.
Note that for .Net on Windows you should not need to export the certificate because the certification authority (CA), Trustwave, is trusted by Windows and the .Net framework SSL/TLS policy is based on the Windows host.
To avoid this for BitDefender go to the settings and disable the “Scan SSL” feature.
Authentication
Web APIs often follow a similar pattern for identifying the source of the traffic: they provide you an API key that you’ll present, along with your standard credentials (username and password), each time you want to authenticate.
Once you’ve been correctly identified by the server it returns you another token that you’ll pass around in each of the subsequent requests that require an authenticated user.
This is exactly the same functioning for a standard web session: you authenticate with the server typically by filling an HTML form using your favorite web browser, the server emits a session cookie that is sent back to the browser; the browser stores this cookie locally and presents it for each subsequent HTTP requests it sends to the web server.
In the Cometdocs API you obtain a new session token using the authenticate entry-point, and you provide this token with all your subsequent authenticated requests.
When you’re done with your session, e.g. when you log out of a web site, you simply ask the server to invalidate the token so that it cannot be used in the future by an attacker who could have stolen it.
In the Cometdocs API this task is handled by the invalidateToken entry-point: you give it a token you do not want to use anymore, so it’s invalidated and the API will then reject any subsequent request that uses this token and instead will emit an “Invalid token” error.
Errors management
Cometdocs representation
Sometimes something bad happens and the Cometdocs API screams at you with a special error response that holds all the necessary info for troubleshooting:
- the “status“: a numerical code
- the “message“: a short human readable message
- the “error“: sometimes an additional more explicit message
As an example if I request the content of a folder using an invalid session token the Cometdocs API replies:
{"status":5,"message":"Invalid token"}
The list of all the possible errors is available here: Status Codes.
Object-oriented mapping
As object oriented programmers we are used to manage errors with exceptions: an exception being just an object that carries some information from the place where the error happens to the place where the error is handled.
At the web API level there is no such thing as an exception, but only some special objects representing an erroneous state.
All the error responses have been mapped to exceptions and a basic exceptions hierarchy have been created with a generic class at its root: the “CometDocsException” class; and the numerical codes have been mapped to a dedicated enum.
To simplify development and maintenance I’ve not created a dedicated exception class for each of the possible errors but only for the more frequent.
Here is a simplified class diagram:
+--------------------+
| <<enumeration>> |
| Status |
+--------------------+
| OK |
| InternalError |
| ... |
+--------------------+
+-----------------------+
| CometDocsException |
+-----------------------+
| status : Status |
| message : string |
| error : string |
+-----------------------+
^
|
+-----------------------+
| InvalidTokenException |
+-----------------------+
| |
+-----------------------+
(and yes, I’m not an UML purist)
Responses handling
The error detection is done upfront, as soon as the Cometdocs API response is interpreted; a dedicated method named “checkAndThrow” is responsible for:
- detecting if the response represents and error
- if yes for building the correct exception instance
- and finally for throwing the exception
As the error management is centralized in this method, the only thing the API binding methods have to do when they receive the response if to pass it to the “checkAndThrow” method and to continue executing if all is fine.
As an example here is what the “authenticate” method does in the Java implementation:
AuthenticateResponse response = gson.fromJson(json, AuthenticateResponse.class); checkAndThrow(response); return new AuthenticationToken(response.getToken());
If the “response” object is an error the “checkAndThrow” method throws an exception which bubbles up to the caller of the “authenticate” method which should handle it.
Otherwise if all is fine the execution flow continues and the “authenticate” method finishes, returning the authentication token.
Testing
As you know testing is critical but is more or less easy to implement depending on the type of components under test.
And a web API is really not the most trivial thing to test because you’re interacting with an external system, and you can’t mock anything, like the network, because it is an integral part of what you’re testing.
Implementations: Java, .Net/C#
Test fixture setup
The implementation of the set of tests gave me the opportunity to use a test fixture setup, i.e. an operation that is executed once before launching all the unit-tests.
Its role is to ensure that all is in place for the tests to run correctly: e.g. if you can’t connect to the Cometdocs API it’s useless to launch the tests because all will fail.
Here are the preconditions tested by the setup method:
- the presence of the credentials file, because without the credentials authentication is impossible
- the ability to authenticate with the Cometdocs API
- the existence of a folder dedicated to testing to avoid messing up a Cometdocs store
If any fails then the test run is aborted.
Note that it’s kind of a catch-22 situation because to start the tests, including the test that checks that we can get a folder, we need to use the method that gets a folder.
Implementations: Java, .Net/C#
Mailing or not mailing
When you’re testing you’re sometimes getting frustrated because some behaviors are hard to test in a fully automated manner.
Concerning the Cometdocs API I’ve been able to test everything from simple operations like authentication to composite operations like uploading, converting and downloading a file; well everything except one thing: automatic mailing.
Indeed the sendFile method triggers the sending of an email to the recipients of your file.
Checking that the email has been received is possible by talking to the mail servers, e.g. the POP Gmail server at “pop.gmail.com” with a POP client like OpenPop.
But doing so will expose you to another complex external layer with its own issues: e.g. Gmail POP servers can return a bad numbers of messages unless you do some extra work to configure it (and yes I’ve tested it!).
You could create a dedicated email address to avoid this issue and clean it at the end of the test so you’re always able to get new messages…
As this is a secondary issue I was clearly crossing the line and finally reduced this part of the “sendFile” method test to this:
// Assert you've received the email
Well, no need to say that this assertion always pass even without internet connectivity 😉
This is all good for now and full testing has been postponed to an unknown date…
Am I missing something
As you saw above, the Cometdocs API has a getMethods entry-point that returns the list of the signatures of all the entry-points supported by the API.
As of now here is what hitting “https://www.cometdocs.com/api/v1/getMethods” returns:
{
"methods":
[
"authenticate(clientKey, username, password, validity=null)",
"refreshToken(token, validity=null)",
"invalidateToken(token)",
"getFolder(token, folderId=null, recursive=0)",
"getConversions(token, fileId=null, includeAvailable=0, includeRunning=0)",
"downloadFile(token, id)",
"uploadFile(token, folderId=null)",
"uploadFileFromUrl(token, url, name=null, folderId=null)",
"convertFile(token, id, conversionType)",
"getConversionStatus(token, fileId, conversionType)",
"getSharedFiles(token)",
"getNotifications(token)",
"deleteFile(token, id, deleteRevisions=1)",
"deleteFolder(token, id)",
"getConversionTypes()",
"getCategories()",
"getPublicFiles(token, categoryId=null)",
"sendFile(token, id, recipients, sender=null, message=null)",
"createFolder(token, name, folderId=null)",
"createAccount(name, email, password)",
"getMethods()"
],
"status":0,
"message":"OK"
}
(output reformatted by me for clarity)
So to ensure that the binding is complete we can compare the list of implemented methods against the list of available methods; if one is missing because it was forgotten or added later, or if one is present but no more into the official API, we can be warned immediately.
This is typically the kind of test you run on a regular basis to automatically be informed that a new feature is available and that you should update your language binding.
And it proved to be very useful: one time, when running my unit-tests for something completely different, I’ve noticed that this test was broken, so I retrieved the new list and the list of currently implemented methods and a quick comparison with Excel revealed the culprits: createFolder and getConversionStatus had been added.
I’ve not tested the parameters themselves, so the testing is partial and is based only on the names; and I’ve not created a high-level representation of a “method” because this kind of object is not intended for the common user who only wants to play with its documents, but is only useful for the binding developer who wants to check its implementation.
Technically this test is based on reflection, i.e. the ability for a program to dynamically discover properties of objects.
Reflection is one of these features often over-abused but that when used wisely can reveal incredibly powerful.
Implementations: Java, .Net/C#
Check your limits
When you start to automate your tests you must take care of limiting their impact on production systems, particularly if you work with a continuous integration software which will launch tests for each successful build, which can happen often if you have a lot of code source commits.
I’ve worked in a team where we had some troubles: there was a bunch of tests, a part of them directly testing some critical production systems, launched using Hudson/Jenkins, sometimes ten times in less than one hour, with a not so negligible impact on the systems under test!
More anecdotal, while testing relatively heavily some features of the Cometdocs API I’ve broken my API requests limits, but thanks to the reactivity of the API development team my limits were raised allowing me to test without having to worry about any limitations, but of course keeping things at a reasonable level to avoid any overload.
The human factor
The API is only the tip of the iceberg, hiding the implementation, and behind this implementation there is a team of humans you may need to interact with, for these reasons:
- request some help to understand and use some features if the documentation is not sufficient,
- notify of bugs your tests may have revealed,
- ask for the implementation of new features or enhancements of existing ones.
If you can’t talk to anybody, implementing your binding can be really painful and you remain lost with your questions and issues.
Happily for me the Cometdocs development team was technically strong and very reactive: I got technical feedback to the point for all my issues.
e.g., as mentioned above, my API limits were raised quickly to allow me to strengthen my tests.
Sometimes bugs were fixed or new features implemented from one day to the next.
Conclusion
As you see implementing a language binding is not that terrible once you know how to use the building blocks like HTTP, SSL, XML and JSON.
For me this was a great experience especially because it was the first time I developed something for two platforms, Java and .Net.
If you are a technology troll you might hope that I reveal that one of Java or .Net was more productive, but this was not the case: I’ve basically had the same difficulty with both and the implementation times were really similar.
Here is an example of how things can balance: while, IMHO, the WebClient is a simpler component than the Apache HttpClient it does not have builtin support for file uploads which forced me to go deeper, at the HTTP layer level, to implement it.
Concerning the security .Net was easier to use because its SSL/TLS security management is integrated with the host system so you don’t have to worry about importing the Cometdocs certificates as it should already be trusted by your system; I’m not sure which of Java or .Net approach is the better but from my modest implementer point of view the plug-and-play effect was appreciated.
I hope this article has helped you get a better understanding of the ins and outs of the implementation of a language binding for a web API.
If you want me to clarify or develop some points do not hesitate to ask I’ll try my best to update the article accordingly.
If you’ve already implemented this kind of language binding I’d like to hear from you, so please share your experience by letting a comment.